Data warehouse, the English name is Data Warehouse, which can be abbreviated as DW or DWH. Data warehousing is a set of strategies that provide support for all types of data for all levels of decision making in the enterprise. It is a single data store created for analytical reporting and decision support purposes. Provide guidance to business process improvement, monitoring time, cost, quality, and control for businesses that require business intelligence.
A data warehouse is a structured data environment for decision support systems (dss) and online analytical application data sources. Data warehousing studies and solves the problem of getting information from a database. Data warehouses are characterized by topic-oriented, integration, stability, and time-varying. The data warehouse, proposed by Bill Inmon, the father of the data warehouse, in 1990, is still the bulk of the data accumulated by the organization through the online transaction processing (OLTP) of the information system over the years, through the data warehouse theory. The unique data storage architecture is systematically analyzed and organized to facilitate various analysis methods such as online analytical processing (OLAP) and data mining (Data Mining), and then support such as decision support systems (DSS) and supervisors. The creation of the Information System (EIS) helps decision makers to quickly and effectively analyze valuable information from a large amount of data to facilitate decision making and rapid response to external environmental changes, helping to build business intelligence (BI).
Multidimensional databaseMulti Dimensional Database (MDD) can be simply understood as: storing data in an n-dimensional array instead of storing it as a relational database. So it has a large number of sparse matrices, and people can observe the data through multidimensional views.
Multidimensional databases refer to storing data in a gate-dimensional array rather than as a relational database. So it has a large number of sparse matrices, and people can observe the data through multidimensional views. Multidimensional database adds a time dimension. Compared with relational database, it has the advantage of improving data processing speed, speeding up response time and improving query efficiency.
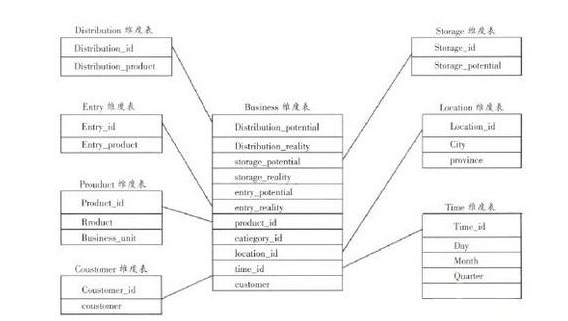
There are two types of database design models widely used in data warehousing: relational and multidimensional. It is generally believed that in the data warehouse design method, the relational model is the "Inmon" method and the multidimensional model is the "Kimball" method.
Let's look at the relational model first. Relational data exists in a form called "standardization." Data standardization means that the database design decomposes the data into a very low level of granularity, and the standardized data exists in an isolated mode. In this case, the data relationship in the data table is very strict. Generally follow the 3NF paradigm. Databases with relational design are generally more flexible and versatile (can support multiple views of data).
Looking at the multidimensional model, the multidimensional model generally has a star schema, a snowflake mode, and a promiscuous mode (also called a galaxy mode). The biggest advantage of multidimensional model design is the efficiency of access.
The difference between the two modelsAs the basis of data warehouse design, there are many differences between star connections and relational structures. The most important difference is in terms of flexibility and performance. The relationship model is highly flexible, but it is not ideal for users in terms of performance. Multidimensional models are very efficient in meeting user needs, but they are not very flexible.
Another important difference is the range of design. Inevitably, multidimensional design can only be done within a limited scope, that is, database design can only be optimized under a set of request processes. If all the different group requests are added to the design, optimization becomes meaningless.
When using a relational model, there is no special optimization method in terms of performance. Since the relational model requires data to be stored at the lowest level of granularity, new data can be added without restrictions. Obviously, adding data to a relational model will never stop. Because of this, relational models are suitable for large-scale data (such as an enterprise model), while multidimensional models are suitable for small-scale data (such as a department or even a sub-sector).
The origin of the difference:
The relationship environment is designed from the origin data model. The multidimensional model is modeled on the request of the end user. In other words, the relational model is designed with pure data models and other patterns, while multidimensional models are shaped by processing requests.
In terms of applicability: Since the relational model is formed by abstract data, the model itself is very flexible. But this flexibility is not optimized for the execution of direct data access. If you want a high-performance relational model, the best approach is to extract the data from the model and reconstruct a pattern that is suitable for fast access.
Multidimensional models are fast and efficient in terms of direct access to data. From an architectural point of view, the relational model is a better model for supporting data warehousing in terms of data warehouse design. The reason is that data warehousing needs to support many different user groups according to different agendas and multiple observations. . In other words, the data warehouse is not optimal for accessing a given user. Instead, a data warehouse can support multiple different users in a variety of ways.
Relationship mode, data is stored in the lowest granularity and standardized form; the relationship between relational tables is defined and contains a keyword table with foreign keys; the new table can define new summary and screening criteria for the basic data set in the relational table That is to say, it is very easy to create relational tables in one form and then reshape them in another form, which is ideal for data warehousing environments.
In addition, the relationship model supports the unmet need in the future, and the need to support moderate changes has the advantage that the multidimensional model can't match.
So from the reasons discussed above, it can be seen that the relational model is the ideal basis for data warehousing, and star connections are best for data marts.
The difference between an independent market and a subordinate market:An independent marketplace is a data mart created directly through historical applications. Establishing an independent data mart does not require a “global thinking†consideration.
Corresponding to independent data marts are subordinate data marts. A subordinate data mart is built using data from a data warehouse. Its data source does not depend on historical data or operational data, it only depends on the data warehouse. In summary, subordinate data marts require prior planning, long-term observation, global analysis, and cooperation and coordination of demand analysis by different departments of the enterprise.
After establishing multiple independent data marts, users will soon find that the information between the data marts is not uniform and not synchronized, and every additional data mart will have the problem of increasing detail data redundancy. A large amount of resources to build interface programs, and maintaining these programs has become a burden. Therefore, independent data marts are not suitable for solving information problems in enterprises.
Of course, if an enterprise adopts a subordinate data mart and creates a data warehouse before building any data mart, then the architectural aspects inherent in the independent data mart will not arise.
In other words, independent data marts represent a short-term, limited-range solution that does not require global and panoramic views. On the other hand, subordinate data marts require a long-term and global outlook. But independent data marts do not provide a solid foundation for corporate information, and subordinate data marts do provide a true long-term basis for information decision making.
| About Film Covered Wire |
Glass-fiber covered polyester film covered rectangular copper (aluminium) wire .includings Glass-fiber Polyimide Film Covered flat Copper wire, Glass-fiber Polyimide Film Covered flat Aluminium wire, Glass-fiber Polyester Film Covered flat Copper wire, Glass-fiber Polyester Film Covered flat Aluminium wire, Glass-fiber Covered flat Copper wire, Glass-fiber Covered flat Aluminium wire.
Packaging of Products
30/50/150 kg wooden spool
Application: medium and large electrical motor and transformer windings

Aluminium Wire,Film Covered Wire,Polyimide Film Covered Copper Wire,Film Covered Flat Wire
HENAN HUAYANG ELECTRICAL TECHNOLOGY GROUP CO.,LTD , https://www.huaonwire.com