Lei Feng Network (search "Lei Feng Network" public concern) by: Zhang Wei, the author of this article , Institute of Computing Technology, Chinese Academy of Sciences VIPL team of doctoral students, focusing on deep learning technology and its application in the field of face recognition. Relevant research results were published in ICCV, CVPR and ECCV, the top international academic conferences of computer vision, and served as reviewers of top international journals TIP and TNNLS.
The facial feature point positioning task automatically locates facial key feature points such as eyes, nose tips, mouth corner points, eyebrows, and contour points of various parts of the face according to the input face image, as shown in the following figure.
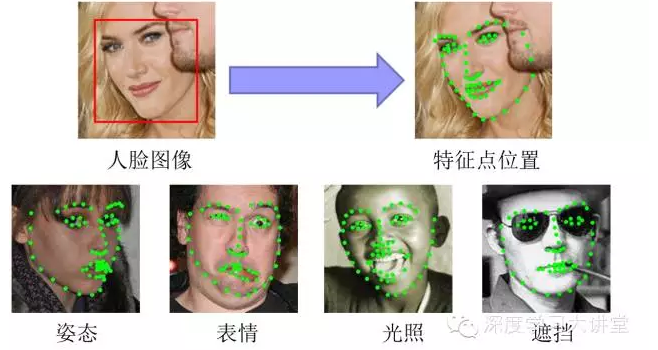
This technology is widely used, such as automatic face recognition, face recognition, and automatic synthesis of face animation. Due to the influence of different postures, expressions, lighting, and occlusion, it may seem difficult to accurately locate each key feature point. When we briefly analyze this issue, it is not difficult to find that this task can actually split three sub-problems:
How to model face image (input)
How to model face shape (output)
How to establish association between face appearance image (model) and face shape (model)
The previous research work can not be separated from these three aspects. The typical methods of face shape modeling include Deformable Template, Point Distribution Model (Active Shape Model), and Graph Model .
Face appearance modeling can be further divided into global appearance modeling and local appearance modeling. Global appearance modeling is simply to consider how to model the entire face's apparent information. The typical methods are Active Appearance Model (active model) and Boosted Appearance Model (discriminative model). The corresponding local apparent modeling is modeling the apparent information of the local area, including the color model, the projection model, the side profile model, and the like.
Recently, the cascading shape regression model has made a major breakthrough in the feature point positioning task. This method uses a regression model to directly learn the mapping function from the face appearance to the face shape (or the parameters of the face shape model), and then establishes The correspondence from appearance to shape. Such methods do not require complicated face shape and appearance modeling, and are simple and highly efficient. They achieve good positioning in controllable scenes (faces collected under laboratory conditions) and non-controllable scenes (network face images, etc.). Effect . In addition, facial feature point location methods based on deep learning have also achieved remarkable results. Deep learning combined with shape regression framework can further improve the accuracy of the positioning model and become one of the mainstream methods for current feature positioning. In the following, I will introduce in detail the research progress of the two methods of cascading shape regression and deep learning.
Cascaded linear regression modelThe facial feature point location problem can be seen as learning a regression function F, taking image I as input, and outputting θ as the position of the feature point (face shape): θ = F(I). In simple terms, the cascading regression model can be unified into the following framework: learning multiple regression functions {f1,..., fn-1, fn} to approximate function F:
θ = F(I) = fn (fn-1 (...f1(θ0, I), I), I)
Θi= fi (θi-1, I), i=1,...,n
The so-called cascade, that is, the input of the current function fi depends on the output θi-1 of the function fi-1 of the previous stage, and the learning target of each fi is the real position θ of the approximated feature point, and θ 0 is the initial shape. In general, fi does not directly return to the true position θ, but returns the difference between the current shape θi-1 and the real position θ: Δθi = θ - θi-1.
Next, I will introduce several typical shape regression methods in detail. Their fundamental difference is that the design of function f i is different and the input features are different.
Piotr Dollár, a postdoctoral researcher at Caltech, first proposed Cascaded Pose Regression (CPR), a cascading shape regression model, to predict the shape of objects in 2010. This work was published in the International Computer Vision and Pattern Recognition Conference CVPR. As shown in the figure below, given the initial shape θ0, which is generally the average shape, the feature (difference between two pixels) is extracted as the input of the function f1 based on the initial shape θ0. Each function fi is modeled as a Random Fern Regressor to predict the difference Δθi between the current shape θi-1 and the target shape θ, and updates the current shape according to the ΔӪi prediction result to obtain θ i = θi-1 + ΔӪi as a next-order function. Fi+1 input.
The method obtains good experimental results on three data sets of face, mouse and fish. The general algorithm framework can also be used for other shape estimation tasks such as human pose estimation. The disadvantage of this method is that it is sensitive to the initialization shape θ0. Using multiple initializations to make multiple tests and merging multiple prediction results can alleviate the influence of initialization on the algorithm to some extent, but it cannot completely solve the problem and it is Testing will incur additional computational overhead. When the target object is occluded, performance also deteriorates.
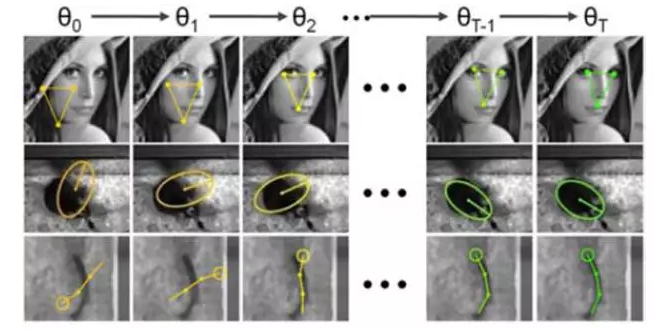
Xavier P. Burgos-Artizzu, who was from the same task group as the previous work, proposed the Robust Cascaded Pose Regression (RCPR) method for the insufficiency of the CPR method and published it at the 2013 International Computing Vision Conference ICCV. In order to solve the occlusion problem, Piotr Dollár proposes to simultaneously predict whether the face shape and feature points are occluded, ie, the output of fi contains Δθi and whether each feature point is occluded in the state pi:
{Δθi, pi }= fi(θi-1, I), i=1,...,n
When some feature points are occluded, the features of the area where the feature points are located are not selected as input, so as to avoid the interference of occlusion to positioning. In addition, the author proposes an intelligent restart technique to solve the problem of shape initialization sensitivity: randomly initialize a set of shapes, run the first 10% of the functions {f1,...,fn-1,fn}, and statistically predict the variance of the shape prediction if the variance is less than certain The threshold value indicates that the initialization of this group is good, then the remaining 90% of the cascaded functions are run, and the final prediction result is obtained. If the variance is greater than a certain threshold, it indicates that the initialization is not ideal, and a set of shapes is reinitialized. The strategy is straightforward but it works well.
Another very interesting task, the Supervised Descent Method (SDM), considers the problem from another perspective, namely how to use the method of supervising gradient descent to solve the nonlinear least squares problem, and successfully apply it to facial feature point positioning tasks. It is not difficult to find that the final algorithm framework of this method is also a cascading regression model.
The difference between CPR and RCPR is that fi modeling is a linear regression model; the input of fi is the SIFT feature related to the face shape. The extraction of this feature is also very simple, ie a 128-dimensional SIFT feature is extracted at each feature point of the current face shape θi-1, and all SIFT features are connected together as an input of fi.
This method obtains good positioning results on the LFPW and LFW-A&C datasets. Another work DRMF in the same period is to use the support vector regression SVR to model the regression function fi, and use the shape-related HOG features (similar to the shape-related SIFT extraction method) as the fi input to cascade predict the face shape. The biggest difference from SDM is that DRMF parametrically models face shapes. The goal of fi becomes to predict these shape parameters and is no longer a direct face shape. Both of these jobs were also published at CVPR 2013. Since the face shape parameterization model is difficult to perfectly describe all the shape changes, the actual measurement effect of SDM is better than that of DRMF.
A team of researchers from Microsoft Asia Research Institute Sun Jian proposed a more efficient method of Regressing Local Binary Features (LBF) at CVPR 2014. Similar to SDM, fi is also modeled as a linear regression model; the difference is that SIFT uses SIFT features directly, and LBF learns sparse binarization features in local regions based on a random forest regression model. By learning the sparse binarization feature, it greatly reduces the computational overhead and has a higher operating efficiency than CRP, RCPR, SDM, DRMF and other methods (LBF can run to 300FPS on mobile phones), and it is excellent on the IBUG public evaluation set. For SDM, RCPR performance.
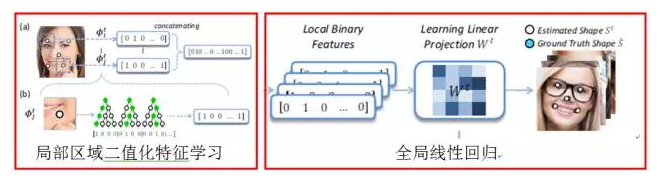
The key to the success of the cascading shape regression model is:
1. The use of shape-dependent features, ie the input of the function fi is closely related to the current face shape θi-1;
2. The target of the function fi is also related to the current face shape θi-1, that is, the optimal target of fi is the difference Δθi between the current shape θi-1 and the real position θ.
Such methods achieve good positioning results in both controlled and uncontrollable scenarios, and have good real-time performance.
Depth model
The cascading shape regression method introduced above is a shallow model (linear regression model, Random Fern, etc.) for each regression function fi. Deep network models such as Convolutional Neural Networks (CNN), Deep Self-Encoder (DAE), and Restricted Boltzmann Machines (RBM) in computer vision problems such as scene classification, target tracking, and image segmentation Has a wide range of applications, of course, also includes feature location issues. The specific methods can be divided into two categories: the use of depth models to model changes in face shape and appearance, and the depth-based learning of nonlinear mapping functions from face appearance to shape.
The active shape model ASM and the active appearance model AAM use principal component analysis (PCA) to model changes in the face shape. Because of the influence of gestures and expressions, it is difficult for the linear PCA model to perfectly depict the change of face shape under different expressions and postures. Professor JiQiang's research group from Rensselaer Polytechnic Institute proposed the use of a deep belief network (DBN) at CVPR2013 to characterize the complex nonlinear changes in human face shape under different expressions. In addition, in order to deal with the problem of feature point location in different poses, a 3-facet RBM network is further used to model face shape changes from frontal to non-frontal. Finally, this method obtains a better positioning result than the linear model AAM on the expression database CK+. The method has a database with multiple gestures and multiple expressions at the same time
ISL also achieved better positioning results, but it is not ideal for extreme situations and exaggerated facial expressions.
The following figure is a diagram of a deep belief network (DBN): modeling changes in face shape under different expressions.

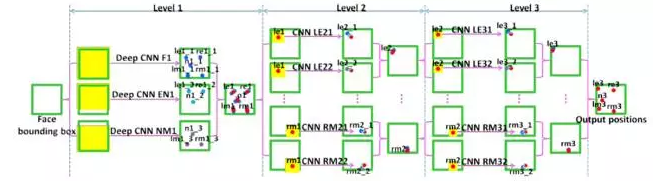
Prof. Tang Xiaoou of the Chinese University of Hong Kong presented at the CVPR 2013 a three-level convolutional neural network DCNN to achieve facial feature point location. This method can also be unified under the large framework of cascaded shape regression models. Unlike CPR, RCPR, SDM, LBF, etc., DCNN uses depth model-convolutional neural network to achieve fi. The first level f1 uses three different regions of the face image (the entire face, eye and nose regions, nose and lip regions) as input, and trains three convolutional neural networks to predict the position of feature points. The network structure contains Four convolutional layers, three Pooling layers, and two fully connected layers, and incorporate three network predictions to obtain more stable positioning results.
The next two levels f2, f3 extract features near each feature point, and train a convolutional neural network (2 convolution layers, 2 Pooling layers, and 1 fully connected layer) for each feature point to correct the positioning result. . This method obtains the best positioning results at the time on the LFPW data set.
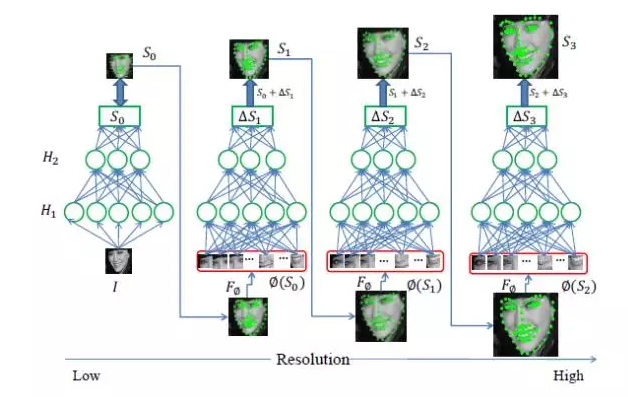
I also took the opportunity to introduce myself to the work of the European Visual Conference ECVC 2014: a coarse-to-fine self-encoder network (CFAN) was proposed to describe the complex nonlinear mapping process from face appearance to face shape. The method cascades a plurality of stacked self-encoder networks fi, each of which depicts a partial nonlinear mapping from face appearance to face shape.
Specifically, a low-resolution face image I is input, and the first layer of the self-encoder network f1 can quickly estimate the approximate face shape as a global self-encoding stack-based coding network. Network f1 contains three hidden layers. The number of hidden layer nodes is 1600, 900, 400 respectively. Then, the resolution of the face image is increased, and the joint local feature is extracted according to the initial face shape θ1 obtained from f1, and input to the next layer of the self-encoder network f2 to simultaneously optimize and adjust the positions of all the feature points, and is recorded as local based. Characteristic stack self-encoding network. This method cascades three locally stacked self-encoding networks {f2, f3, f4} until convergence on the training set. Each locally-stacked self-encoding network consists of three hidden layers. The number of hidden layer nodes is 1296,784,400 respectively. Thanks to the powerful nonlinear modeling ability of the depth model, this method achieves better results than DRMF and SDM on the XM2VTS, LFPW, and HELEN data sets. In addition, the CFAN can complete the facial feature point location (23 milliseconds/piece on the I7 desktop) in real time, which has a faster processing speed than DCNN (120 milliseconds/piece).
The following figure is a schematic diagram of a CFAN: based on a real-time facial feature point localization method from a coarse to fine self-encoder network.
The above method based on cascading shape regression and deep learning can achieve better positioning results for large gestures (around -60°~+60° rotation) and various expression changes, and has a fast processing speed and good product application prospects. . The solution to the problem of pure side (±90°), partial occlusion, and joint detection of face detection and feature location is still the current research hotspot.
In addition, regarding face detection: face detection development: from VJ to deep learning (top), face detection development: from VJ to deep learning (bottom).
Lei Fengwang Note: This article was authorized by the Deep Learning Lecture Center to be published by Lei Feng. Reprinted, please contact the authoritative and retain the source and the author, not to delete the content.
