The text chapter is selected from "Introduction and Practicality of Natural Language Processing Technology"
Another important area of ​​application in natural language processing is the automatic writing of text. Keywords, key phrases, and automatic abstract extraction are all applications in this field. However, these applications are generated by more or less. Here we introduce another application: generation from small to many, including the rewriting of sentences, generating articles or paragraphs from keywords, topics, and so on.
Automatic text generation model based on keywords
The first section of this chapter introduces some processing techniques for generating a piece of text based on keywords. It is mainly implemented by techniques such as keyword extraction and synonym recognition. The implementation process is described and introduced below.
Scenes
When doing search engine advertising, we need to write a sentence description for the ad. In general, the input of the model is some keywords. For example, the advertisement we want to deliver is a flower advertisement, assuming that the keywords of the advertisement are: "flowers" and "cheap". For this input we want to generate a certain number of candidate sentence descriptions.
For this kind of scene, it is also possible to input a sentence. For example, I have manually written an example: "This weekend, the white flowers are only 99 yuan, and they are also 包邮, but also 包邮!". According to this sentence, a certain number of statements that differ in expression but have similar meanings need to be rewritten. Here we introduce a keyword-based text (one sentence) automatic generation model.
principle
The model processing flow is shown in Figure 1.
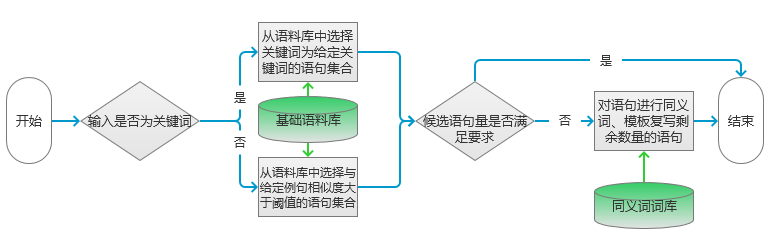
figure 1
First, different processing is performed depending on the type of data input. If the keyword is entered, the same sentence as the keyword is selected in the corpus. If you enter a sentence, then select a sentence in the corpus that is similar to the input statement with a degree of similarity greater than the specified threshold.
The algorithm for keyword extraction in the corpus of the corpus is performed using the method described in the previous section. For specific algorithm choices, you can choose freely according to your own corpus. 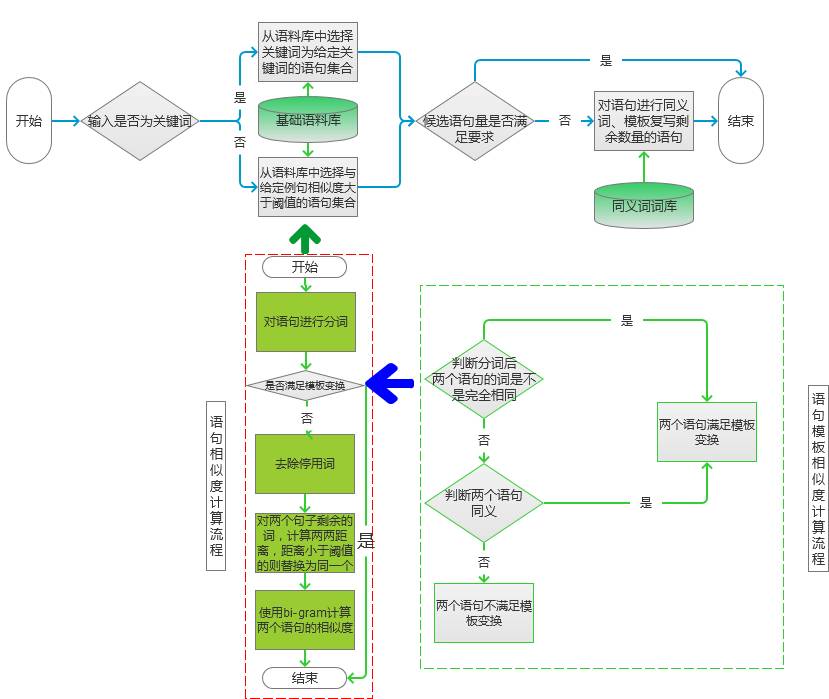
figure 2
The statement similarity calculation, here is calculated according to the flow in the dotted line box on the left side of Figure 2:
First, the two sentences to be processed are processed by word segmentation, and the sentence after the word segmentation is judged whether it satisfies the template transformation. If it is satisfied, the statement is directly put into the candidate set, and the similarity is set to 0. If not, go to step c) for calculation.
Determine whether the two statements satisfy the flow chart of the template transformation, as shown in the flow marked by the dotted line on the right in Figure 2: (1) After judging the word segmentation, the words of the two sentences are not exactly the same, but only the position is different. Yes, the conditions for the template transformation are met. (2) If the words are not identical, look at whether the synonym transformation can be performed between different words. If the synonym transformation can be performed, and the transformed sentence two sentences go to the collection of common words, if the collection is a certain sentence The set of all words of the word also satisfies the template transformation condition. (3) If the above two steps are not satisfied, the template transformation is not satisfied between the two sentences.
Calculate the word distance for the remaining words of the two sentences. If the remaining words in the two sentences are, sentence 1: "flowers", "how much money", "package". Sentence 2: "flowers", "cheap", "free shipping". Then its distance matrix is ​​shown in the following table: 
After getting the similarity matrix, replace the similar words in the two sentences with one, assuming that we replace "free shipping" with "package" here. Then the word vector of the two sentences becomes: sentence 1: <flowers, how much, 包邮>, sentence 2: <flowers, cheap, 包邮>.
For the two sentences to construct the bi-gram statistical vector, there are: (1) sentence 1: <begin, flowers>, <flowers, how much money>, <how much money, 包邮>, <post, end>. (2) sentence 2: <begin, flowers>, <flowers, cheap>, <cheap, 包邮>, <post, end>.
The similarity between these two sentences is calculated by the following formula: 
So the similarity of the above example is: 1.0-2.0*2/8=0.5.
After the extraction of the candidate statement is completed, the subsequent operations are judged based on the number of candidate statements. If the filtered candidate statement is greater than or equal to the required number, the specified number of sentences are selected from low to high according to the sentence similarity. Otherwise, the sentence should be rewritten. Here, the synonym replacement is used and the scheme is rewritten according to the specified template.
achieve
The code to implement the candidate statement calculation is as follows:
Map result = new HashMap();,>,>
If (type == 0) {//Enter as a keyword
Result = getKeyWordsSentence(keyWordsList);
}else {
Result = getWordSimSentence(sentence);
}
//Make the result if the number of candidate sets is greater than or equal to the required number
If (result.size() >= number) {
Result = sub(result, number);
}else {
//Get the result if the number of candidate sets is less than the required number
Result = add(result, number);
}
First, different generation modes are selected according to the input content form for statement generation. The key to this step is the processing of the corpus, the screening of similar keywords and similar sentences. For the screening of keywords, we use the Bloom algorithm, of course, you can also use the index lookup method. For candidate statements, we first use a keyword to make a preliminary screening of the corpus. Determine the more likely statement as the statement for subsequent calculations.
For the candidate results obtained, we save them in the form of a map, where key is the subsequent statement and value is its similarity to the target. Screening is then performed from low to high according to similarity. As for the sorting of maps, we have already introduced them in the previous chapters, and we will not repeat them here.
The code that implements the statement-like filtering calculation is as follows.
For (String sen : sentenceList) {
/ / Treat the recognition of the word segmentation
List wordsList1 = parse(sentence);
List wordsList2 = parse(sen);
/ / First determine whether the two statements meet the target transformation
Boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2);
If (!isPatternSim) {// does not satisfy the target transformation
/ / First calculate the bi-gram similarity of two sentences
Double tmp = getBigramSim(wordsList1, wordsList2);
//The filtering condition here is that the similarity is less than the threshold, because the smaller the similarity of the bi-gram, the more similar the two are.
If (threshold > tmp) {
Result.put(sen,tmp);
}
}else {
Result.put(sen,0.0);
}
}
First, the two sentences to be recognized are segmented, and the result of the segmentation is identified by template conversion. If the condition of template conversion is satisfied, the statement is used as a candidate statement and a minimum probability is assigned. If not, calculate the similarity of the bi-grams of the two. Filter according to the threshold.
The bi-gram used here is improved, and the conventional bi-gram does not need to be scaled. This calculation is done here to avoid the effects of characters of different lengths. For the similarity measure, you can also choose the appropriate measurement method according to your actual situation.
expand
The scenarios handled in this section are: the generation of text to text. This scene generally involves text processing techniques such as text summarization, sentence compression, text rewriting, and sentence fusion. This section covers techniques in both text summaries and sentence rewriting. The text summary is mainly related to the following: keyword extraction, phrase extraction, sentence extraction and so on. Sentence rewriting can be roughly divided into the following according to the different means of implementation.
A method based on the rewriting of synonyms. This is also the way this section uses, which is lexical-level and can largely guarantee that the replaced text is consistent with the original semantics. The disadvantage is that the smoothness of the sentence will be reduced. Of course, the hidden Markov model can be used to correct the sentence collocation and improve the overall effect.
Template-based rewriting method. This is also the way this section uses. The basic idea of ​​the method is to statistically summarize the fixed templates from a large collection of corpus, and the system decides how to generate different expressions according to the matching of the input sentences with the template. Suppose there is a template as follows.
Rzv n, aa ——> aa, rzv n
Then for (input): this /rzv, flowers / n, true / a, cheap / a can be converted to (output): true / a, cheap / a, this / rzv, flowers / n This method is characterized by easy Implementation, and processing speed, but the problem is that the versatility of the template is difficult to grasp, if the template design is too rigid, it is difficult to deal with complex sentence structure, and the language phenomenon that can be processed will be subject to certain constraints. If the template is designed to be too flexible, it often produces a wrong match.
A rewriting method based on statistical models and semantic analysis generation models. This type of method is based on the data in the corpus, obtains a large number of conversion probability distributions, and then replaces the input corpus with known prior knowledge. The sentences of such methods are generated on the basis of the analysis results. In a sense, the generation is realized under the guidance of the analysis. Therefore, the sentences generated by the rewriting may have a good sentence structure. But the corpus on which it depends is very large, so you need to manually label a lot of data. For these issues, new deep learning techniques can solve some of the problems. At the same time, combined with the deep learning of knowledge maps, we can make better use of human knowledge and minimize the data requirements for training samples.
RNN model implements automatic text generation
Section 6.1.2 describes some of the processing techniques for obtaining long text based on short text input. The main use here is the RNN network, which uses its ability to process sequence data to auto-fill text sequence data. The following is a description and introduction to the implementation details.
Scenes
In the process of advertising, we may encounter this kind of scenario: a paragraph of description text is generated by a sentence, and the length of the text is between 200 and 300 words. Inputs may also be keywords for some topics.
At this point we need an algorithm that produces a lot of text based on a small amount of text input. Here is an algorithm: RNN algorithm. We have introduced this algorithm in Section 5.3, which uses this algorithm to convert from pinyin to Chinese characters. In fact, the patterns of the two scenes are the same, and all the text information is generated by the given text information. The difference is that the former is to generate the Chinese character corresponding to the current element, and here is to generate the next Chinese character corresponding to the current element.
principle
As with Section 5.3, we are still using the Simple RNN model here. So the entire calculation flow chart is shown in Figure 3.
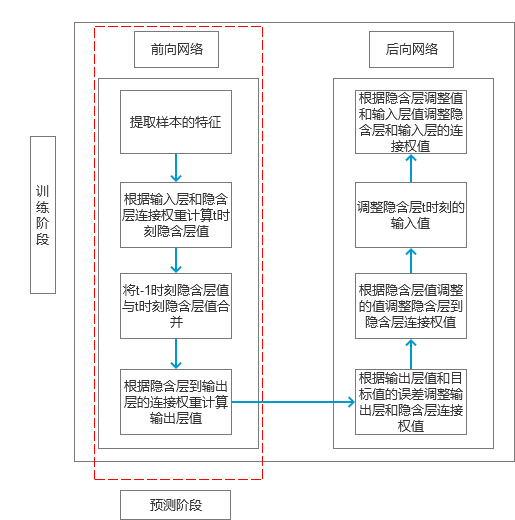
image 3
In the process of feature selection, we need to consider more about the connection between the upper and lower segments, the length of a paragraph of text, the emotional changes in the paragraph, wording transformation and other descriptor extraction. This can better achieve the natural transformation of the article.
In the generated articles, the use of adjectives and adverbs can be given a higher proportion, because adjectives and adverbs generally do not affect the structure of the article, and the expression of meaning, but at the same time increase the appeal of the article. For example, the best, the most beautiful, the cheapest, etc., are basically versatile words, can be combined for different nouns or gerunds, and readers will generally have a desire to deepen understanding.
Words related to the topic can be used in multiple places, and words that are replaced with topics should be replaced with words related to the topic as much as possible. Because this not only improves the consistency of the article, but also increases the exposure of the theme.
These are some of the experiences that have been proposed for advertising scenarios. The patterns of other scenarios may not be suitable, but specific optimization strategies can be determined according to their own scenarios.
The specific calculation process is basically the same as that in Section 5.3, and will not be described here.
Code
The code to implement the feature training calculation is as follows:
Public double train(List x, List y) {[]>[]>
alreadyTrain = true;
Double minError = Double.MAX_VALUE;
For (int i = 0; i < totalTrain; i++) {
/ / Define the update array
Double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length];
Double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length];
Double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length];
List hiddenLayerInput = new ArrayList();[]>[]>
List outputLayerDelta = new ArrayList();[]>[]>
Double[] hiddenLayerInitial = new double[hiddenLayers];
/ / Assign a value of 0 to the initial hidden layer variable
Arrays.fill(hiddenLayerInitial, 0.0);
hiddenLayerInput.add(hiddenLayerInitial);
Double overallError = 0.0;
/ / Forward network calculation prediction error
overallError = propagateNetWork(x, y, hiddenLayerInput,
outputLayerDelta, overallError);
If (overallError < minError) {
minError = overallError;
}else {
Continue;
}
first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length);
Double[] hidden2InputDelta = new double[weightLayerh_update.length];
/ / Backward network adjustment weight matrix
hidden2InputDelta = backwardNetWork(x, hiddenLayerInput,
outputLayerDelta, hidden2InputDelta, weightLayer0_update, weightLayer1_update, weightLayerh_update);
weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha));
weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha));
weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha));
}
Return -1.0;
}
First, the variables to be adjusted are initialized. After completing this step, the forward network is used to predict the input values. After the prediction is completed, the backward network is used to adjust the weight vectors according to the prediction error.
The process to be aware of is that each time the weight update is not a full update, it is updated based on the learning rate alpha. The other steps are basically the same as described previously.
The code to implement the predictive calculation is shown below:
Public double[] predict(double[] x) {
If (!alreadyTrain) {
New IllegalAccessError("model has not been trained, so can not to be predicted!!!");
}
Double[] x2FirstLayer = matrixDot(x, weightLayer0);
Double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh);
If (x2FirstLayer.length != firstLayer2Hidden.length) {
New IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!");
}
For (int i = 0; i < x2FirstLayer.length; i++) {
firstLayer2Hidden[i] += x2FirstLayer[i];
}
firstLayer2Hidden = sigmoid(firstLayer2Hidden);
Double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1);
hiddenLayer2Out = sigmoid(hiddenLayer2Out);
Return hiddenLayer2Out;
}
Before forecasting, it is first necessary to determine whether the model has been trained. If no training is completed, it is necessary to train first to obtain a predictive model. Of course, this is a check related to the specific business logic. This is mainly for the case where the prediction and training are separated. If the training and prediction are in one process, the verification is not necessary.
After the training model is obtained, it is calculated step by step according to the flow of the forward network, and finally the predicted value is obtained. Since we are a classification problem here, we end up choosing the word with the greatest probability as the final output.
expand
The generation of text, according to the input method, can be divided into the following types:
Text to text generation. That is, the input is text, and the output is also text.
Image to text. That is, the input is an image, and the output is text.
Data to text. That is, the input is data, and the output is text.
other. That is, the input form is not the above three, but the output is also text. Because this type of input is more difficult to generalize, it is classified as something else.
Among them, the second and third types have developed very fast recently, especially with the development of cutting-edge technologies such as deep learning and knowledge mapping. Test results based on image-generated text descriptions are constantly being refreshed. The image text generation technology based on GAN (anti-neural network) has realized a very large map, which can not only generate a very good description according to the picture, but also generate a corresponding picture according to the text input.
Text generated from data is currently used primarily in the field of news writing. Both Chinese and English have made great progress. The English is represented by the Associated Press, while the Chinese is represented by Tencent. Of course, neither of these two is purely based on data input, but a combination of the above four situations of news writing.
Technically speaking, there are two mainstream implementation methods: one is symbol-based and represented by knowledge map. This kind of method uses human prior knowledge more, and the processing of text contains more semantics. ingredient. The other is based on statistics (joining), that is, learning the combination law between different texts based on a large amount of text, and then inferring possible combinations according to the input as an output. With the combination of deep learning and knowledge maps, there is a clear convergence between the two, which should be an important node for realizing future technological breakthroughs.
Fiber Optic Distribution Box,Fiber Optic Breakout Box,Fibre Optic Breakout Box,Fibre Break Out Box
Cixi Dani Plastic Products Co.,Ltd , https://www.danifiberoptic.com